|
Игры
Софт
Категории статей
Категории игр
Категории софта
|
|
Новый и обновленный софт
|
|
Наиболее распространенный набор кодеков и программ для просмотра и редактирования аудио- и видео...
|
|
|
Универсальный конвертер видео и аудио файлов, который поддерживает огромное количество форматов.
|
|
|
Avira Free Antivirus - одна из лучших бесплатных антивирусных программ.
|
|
|
Мощный современный медиаплеер.
|
|
|
Самый простой способ управления своими файлами в аккаунте OneDrive. В январе 2014 года компания...
|
|
|
Файловый архиватор с высокой степенью сжатия.
|
|
|
iTunes - это мощный мультимедийный комбайн от компании Apple, который служит для воспроизведения...
|
|
|
Комплекс программ, предназначенный для антивирусной защиты вашего компьютера, работающего на базе...
|
|
|
PuTTY представляет из себя бесплатный Telnet, SSH и Rlogin клиент для операционной системы Windows
|
|
|
Бесплатный видео-конвертер с поддержкой огромного количества форматов.
|
|
|
Приложение предназначается для запуска программ, работающих в сети Интернет, при помощи...
|
|
|
Приложение для мобильных телефонов, работающих на различных операционных системах, которое позволит...
|
|
|
Новый билд самого популярного, надежного и удобного клиент-мессенджера QIP 2012. Помимо этого QIP...
|
|
|
Официальный клиент от сервиса ICQ. Можно общаться не только с контактами ICQ, но и добавлять друзей...
|
|
|
Большой и подробный электронный справочник московских организаций, предприятий с детализированной...
|
|
|
Winamp – самый известный в Рунете проигрыватель аудио, который сейчас стал целой мультимедийной...
|
|
|
Версия Скайпа для мобильных устройств, таких как планшеты и телефоны. Поддерживается большинство...
|
|
|
Бесплатная, удобная и качественно сделанная программа-читалка для электронных книг. Работает на...
|
|
|
Бесплатная программа, созданная для чтения электронных книг на настольных компьютерах и мобильных...
|
|
|
Одна из самых популярных и многофункциональных программ-мессенджеров, созданная для работы на...
|
|
|
Программа дает вам возможность установить прямое и безопасное VPN соединение с компьютерами,...
|
|
|
Один из самых популярных браузеров в РуНете
|
|
|
Кроссплатформенная утилита, работающая как с браузерами, так и приложениями, использующими...
|
|
|
SopCast - это P2P технология, которая дает возможность слушать Интернет радио и смотреть видео...
|
|
|
Несомненно самый популярный бесплатный FTP-клиент, который предназначен для загрузки и скачивания...
|
|
|
Система управления точкой продаж для малых и средних предприятий со встроенным онлайн-магазином,...
|
|
|
Очень быстрый, удобный и простой в использовании браузер, который очень популярен среди...
|
|
|
Это очень популярная программа, которая позволяет осуществлять голосовые и видео-звонки через...
|
|
|
Функциональный, бесплатный медиаплеер, который позволяет использовать себя в качестве сервера для...
|
|
|
Самая последняя версия многофункционального, удобного, безопасного и простого в использовании...
|
|
|
Бесплатный видео-конвертер с поддержкой огромного количества форматов.
|
|
|
Приложение предназначается для запуска программ, работающих в сети Интернет, при помощи...
|
|
|
Программа дает вам возможность установить прямое и безопасное VPN соединение с компьютерами,...
|
|
|
Один из самых популярных браузеров в РуНете
|
|
|
Кроссплатформенная утилита, работающая как с браузерами, так и приложениями, использующими...
|
|
|
SopCast - это P2P технология, которая дает возможность слушать Интернет радио и смотреть видео...
|
|
|
Несомненно самый популярный бесплатный FTP-клиент, который предназначен для загрузки и скачивания...
|
|
|
Система управления точкой продаж для малых и средних предприятий со встроенным онлайн-магазином,...
|
|
|
Новый билд самого популярного, надежного и удобного клиент-мессенджера QIP 2012. Помимо этого QIP...
|
|
|
Очень быстрый, удобный и простой в использовании браузер, который очень популярен среди...
|
|
|
Самый простой способ управления своими файлами в аккаунте OneDrive. В январе 2014 года компания...
|
|
|
Это специальная программа для владельцев домашних компьютеров и мобильных телефонов, позволяющая...
|
|
|
Приложение для мобильных телефонов, работающих на различных операционных системах, которое позволит...
|
|
|
Система управления точкой продаж для малых и средних предприятий со встроенным онлайн-магазином,...
|
|
|
Новый билд самого популярного, надежного и удобного клиент-мессенджера QIP 2012. Помимо этого QIP...
|
|
|
Официальный клиент от сервиса ICQ. Можно общаться не только с контактами ICQ, но и добавлять друзей...
|
|
|
Бесплатная программа для общения посредством веб-камеры и микрофона через интернет, в режиме...
|
|
|
Кроссплатформенная утилита, предназначенная для обмена мгновенными сообщениями между...
|
|
|
Большой и подробный электронный справочник московских организаций, предприятий с детализированной...
|
|
|
Популярная программа, предназначенная для осуществления дешевых звонков на домашние телефоны.
|
|
|
Avira Free Antivirus - одна из лучших бесплатных антивирусных программ.
|
|
|
Самый простой способ управления своими файлами в аккаунте OneDrive. В январе 2014 года компания...
|
|
|
Комплекс программ, предназначенный для антивирусной защиты вашего компьютера, работающего на базе...
|
|
|
Это специальная программа для владельцев домашних компьютеров и мобильных телефонов, позволяющая...
|
|
|
Быстрый и функциональный архиватор, который позволяет создавать и распаковывать архивы всех...
|
|
|
Приложение для мобильных телефонов, работающих на различных операционных системах, которое позволит...
|
|
|
Самый совершенный и быстрый интернет-браузер, разработанный для мобильных устройств различных...
|
|
|
Идеальное решение в плане защиты информации на персональных компьютерах, основанное на ограничениях...
|
|
|
SopCast - это P2P технология, которая дает возможность слушать Интернет радио и смотреть видео...
|
|
|
Система управления точкой продаж для малых и средних предприятий со встроенным онлайн-магазином,...
|
|
|
Бесплатная программа, созданная для чтения электронных книг на настольных компьютерах и мобильных...
|
|
|
Популярная программа, предназначенная для осуществления дешевых звонков на домашние телефоны.
|
|
|
Версия Скайпа для мобильных устройств, таких как планшеты и телефоны. Поддерживается большинство...
|
|
|
Многофункциональный пакет приложений, одновременно являющийся самой настоящей службой безопасности...
|
|
|
Бесплатный и полнофункциональный ICQ-клиент, который предназначен для работы на сотовых телефонах,...
|
|
|
Полнофункциональный медиа плеер для телефонов, работающих на Blackberry OS, поддерживающий...
|
|
|
Бесплатный браузер для мобильных устройств, использующих операционные системы Windows Mobile,...
|
|
|
Foxit Reader заслуженно можно назвать лучшим приложением для просмотра документов в формате PDF
|
|
|
Новый билд самого популярного, надежного и удобного клиент-мессенджера QIP 2012. Помимо этого QIP...
|
|
|
Официальный клиент от сервиса ICQ. Можно общаться не только с контактами ICQ, но и добавлять друзей...
|
|
|
Большой и подробный электронный справочник московских организаций, предприятий с детализированной...
|
|
|
Настоящий водопад у вас дома!
|
|
|
Популярная программа, предназначенная для осуществления дешевых звонков на домашние телефоны.
|
|
|
Программа мгновенного обмена сообщениями через Jaber, для вашего сотового телефона.
|
|
|
VK Client - это java-клиент для телефонов, с помощью которого можно обмениваться мгновенными...
|
|
|
Мобильный клиент для общения ВКонтакте - будьте всегда на связи!
|
|
|
Версия Скайпа для мобильных устройств, таких как планшеты и телефоны. Поддерживается большинство...
|
|
 |
Новые и обновленные игры
|
|
Очень красивая и продуманная MMORPG.
|
|
|
Игра, где вам предстоит почувствовать себя в роли бывалого дальнобойщика, бороздящего дороги...
|
|
|
Очень популярная игра в стиле Defense of Ancients, которая содержит огромное количество преимуществ...
|
|
|
Самая большая и популярная онлайновая игра в мире.
|
|
|
Карточная игра "Храп" для трех игроков.
|
|
|
В игре Alien Shooter вам предстоит сражаться со множеством ужасных монстров, которые сделают все...
|
|
|
Электронный вариант популярной и всеми любимой интеллектуальной игры, известной в мире как «Скрабл»
|
|
|
Набор карт для известной стратегии от Blizzard.
|
|
|
Морской бой v1.2 - игра известная всем с детства. На поле 10 на 10 клеток нужно расставить свои...
|
|
|
Популярная карточная игра, созданная по принципам древней узбекской игры "Свара"....
|
|
|
Очень красивая и продуманная MMORPG.
|
|
|
Очень популярная игра в стиле Defense of Ancients, которая содержит огромное количество преимуществ...
|
|
|
Самая большая и популярная онлайновая игра в мире.
|
|
|
Достаточно простая, но невероятно красивая, привлекательная и увлекательная аркадная игра, давно...
|
|
|
Популярная карта, созданнная поклонниками, для легендарных тактических он-лайн шутеров...
|
|
|
Бесплатная игра, которая позволяет прокатится на огромных скоростях по интересным, разнообразным...
|
|
|
Популярная игра, созданная на основе игровой механики DotA.
|
|
|
Одна из лучших онлайновых гоночных игр от компании EA Black Box
|
|
|
Очередной высококлассный и захватывающий гоночный симулятор из, ставшей уже легендарной, серии Need...
|
|
|
Zuma - это очень стильная аркада с очень простой игровой механикой и красивой графикой, которая...
|
|
|
Peggle - интересная, аддиктивная головоломка от которой просто невозможно оторваться.
|
|
|
Это новая игра во вселенной Lego, которая на этот раз перескажет сюжет пиратской саги о Джеке...
|
|
|
LEGO Harry Potter: Years 5-7 - это интерпретация известной серии книг от Гарри Поттере в виде...
|
|
|
Игра из популярной серии Need for Speed, посвященная круговым гонкам.
|
|
|
Juiced 2: Hot Import Nights - это продолжение автосимулятора, посвященного уличным гонкам, которая...
|
|
|
James Cameron's Avatar: The Game - игра по мотивам одноименной киноленты.
|
|
|
Продолжение культового авиасимулятора.
|
|
|
Split Second: Velocity - это невероятно динамичные и зрелищные гонки.
|
|
|
Очередной высококлассный и захватывающий гоночный симулятор из, ставшей уже легендарной, серии Need...
|
|
|
Limbo - это гениальная инди-игра, которая основана на вашей собственной фантазии.
|
|
|
Аркадные гонки, где нам придется уничтожать ходячих мертвецов.
|
|
|
Тактический шутер от студии Codemasters.
|
|
|
Экшен от первого лица, где игрокам предстоит выступить в качестве отважного снайпера-повстанца.
|
|
|
Zuma - это очень стильная аркада с очень простой игровой механикой и красивой графикой, которая...
|
|
|
Peggle - интересная, аддиктивная головоломка от которой просто невозможно оторваться.
|
|
|
Это новая игра во вселенной Lego, которая на этот раз перескажет сюжет пиратской саги о Джеке...
|
|
|
Insane 2 - аркадные гонки внедорожников с ураганным геймплеем.
|
|
|
Bejeweled 3 - интересная аркада от создателей Zuma и Plants vs. Zombies.
|
|
|
Игра, где вам предстоит почувствовать себя в роли бывалого дальнобойщика, бороздящего дороги...
|
|
|
Самая большая и популярная онлайновая игра в мире.
|
|
|
Безумно интересная и довольно захватывающая игра-головоломка (своеобразный пазл из пересекающихся...
|
|
|
Достаточно простая, но невероятно красивая, привлекательная и увлекательная аркадная игра, давно...
|
|
|
Limbo - это гениальная инди-игра, которая основана на вашей собственной фантазии.
|
|
|
Интересная двухмерная головоломка.
|
|
|
Europa Universalis III - это третья части очень популярной глобальной стратегии в реальном времени.
|
|
|
Making History II: The War of the World - это стратегия, действие которой происходят в преддверии...
|
|
|
Victoria II - это глобальная стратегия, разработанная студией Paradox .
|
|
|
Это интересный хоррор от творцов серии Penumbra.
|
|
|
|
|
Статьи и обзоры
|
|
Все способы открытия Панели управления в Windows 8.
|
|
|
В Avast 2015 улучшена система сканирования и есть интеграция с Windows 10
|
|
|
Подробности о количестве пользователей, доменов и многом другом в итогах 2011.
|
|
|
Инструкция по закрытию профиля в социальной сети Одноклассники.
|
|
|
Инструкция по активации Windows 8 с помощью ключа.
|
|
|
Worms - вечная игра, которая сейчас представлена несколькими десятками версий, а первая из них...
|
|
|
Корпорация Canon расширяет серию объективов EF, выпустив в свет три новых объектива, которыми...
|
|
|
На международной выставке CeBIT, которая сейчас проходит в немецком городе Ганновер, компания Intel...
|
|
|
Компания Nokia уже в следующем месяце планирует выпуск на рынок планшета на базе операционной...
|
|
|
Корпорация Sapphire на выставке CeBIT 2012, проходящей в немецком Ганновере представила графический...
|
|
|
К 2016 году Firefox OS будет доступна пользователям из Штатов и Европы
|
|
|
Подборка из шести популярных программ, необходимых каждому пользователю iPhone
|
|
|
Зачем мне нужен этот Linux? - спросите Вы. Если же Вы простой пользователь и используете компьютер...
|
|
|
Небольшая статья на тему обновления антивируса NOD32.
|
|
|
В недалеком будущем, в рамках кампании по борьбе с непрофильными активами, компания Nokia оставит с...
|
|
|
Туристическая индустрия современности неразрывно связана с совершенствованием технического...
|
|
Статьи и обзоры
|
|
Туристическая индустрия современности неразрывно связана с совершенствованием технического...
|
|
|
Порой в защите информации нуждается даже личный компьютер. Дело в том, что компьютер, подключённый...
|
|
|
Аудит веб-сайта носит рекомендательный характер. Проведение полного аудита позволит на основе...
|
|
|
Google Chrome является, на сегодняшний день, одним из самых продвинутых Интернет-браузеров, который...
|
|
|
Системная плата серии MSI Z77 с Intel архитектурой
|
|
|
Одной из самых продаваемых офисных станций, за последние несколько лет, является флагманская модель...
|
|
|
Если вам нужен хороший и интересный отдых, Корея – это именно то направление, на которое стоит...
|
|
|
В последнее время в жизни многих людей Интернет приобрел огромное значение. Помимо того, что для...
|
|
|
В базовой комплектации коммуникаторов Android не учтена специфика работы владельца, который может...
|
|
|
Рекомендательные сервисы для заядлых игроков
|
|
|
Глядя на резвящихся на батуте детей, невольно начинаешь им завидовать. С какой лёгкостью и...
|
|
|
В Avast 2015 улучшена система сканирования и есть интеграция с Windows 10
|
|
|
К 2016 году Firefox OS будет доступна пользователям из Штатов и Европы
|
|
|
В Windows 10 появится браузер Project Spartan
|
|
|
Инструкция по активации Windows 8 с помощью ключа.
|
|
|
Инструкция по откату системы Windows 8 до более раннего состояния с помощью точки восстановления.
|
|
|
Выбор подходящей программы для очистки Windows 8, и советы, касающиеся мер предосторожности.
|
|
|
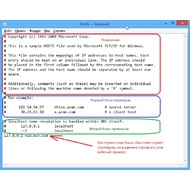
Скриншоты оригинальных файлов hosts, а также некоторые советы по использованию этого файла.
|
|
|
Две программы, которые позволят вам устанавливать будильник на ноутбуке.
|
|
|
Принципы работы с PowerPoint и основные функции программы.
|
|
|